最近做网页分析时接触了一些 包括jsoup在内开源工具。 今天有时间读了下jsoup的源码,记录一下心得。
?
【特色】
作为html 解析工具,jsoup 出现的时间远不如大名鼎鼎的HttpClient。但是他有一些不错的特色:
?
1.实现了CSS选择器语法,有了这个页面内容提取真不是一般的方便。
2.解析算法不使用递归,而是enum配合状态模式遍历数据(先预设所有语法组合),减少性能瓶颈。另外,不需要任何第三方依赖。
?
【示例】
比如要想要过滤一个网页上所有的jpeg图片的链接,只需要下面几句即可。
Document doc = Jsoup.connect("http://www.mafengwo.cn/i/760809.html").get();
Elements jpegs = doc.select("img[src$=.jpeg]");
for (Element jpeg : jpegs) {
System.out.println(jpeg.attr("abs:src"));
}
?没错,这个select()方法的参数用的就是CSS选择器的语法。熟悉JQuery的开发者会觉得非常亲切。
?
【流程分析】
上面的代码可分为三个步骤,后面的源码分析也按照这个思路来走。
1.根据输入构建DOM树
2.解析CSS选择字符串到 过滤表中
3.用深度优先算法将 树状节点逐一过滤
?
【源码分析】
1.DOM树构造
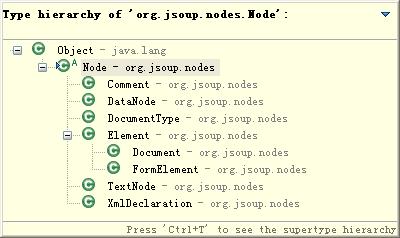
先说一下容器是位于org.jsoup.nodes 下 抽象类 Node及其派生类。看名字就知道意思,典型的组合模式。每个都可以包含子Node列表。其中最重要的是 Element类,代表一个html元素,包含一个tag,多个属性值及子元素。
?
树构造的关键代码位于 模板类TreeBuilder 中:
TreeBuilder类
protected void runParser() {
while (true) {
Token token = tokeniser.read(); // 这里读入所有的Token
process(token);
if (token.type == Token.TokenType.EOF)
break;
}
}
?该类有两个派生类 HtmlTreeBuilder ,XmlTreeBuilder,看名字就知道用途了。这里只看下HtmlTreeBuilder。
?Tokeniser 类
Token read() {
if (!selfClosingFlagAcknowledged) {
error("Self closing flag not acknowledged");
selfClosingFlagAcknowledged = true;
}
while (!isEmitPending)
state.read(this, reader); //此处 在做预设好的各种状态转移 以遍历所有标签
// if emit is pending, a non-character token was found: return any chars in buffer, and leave token for next read:
if (charBuffer.length() > 0) {
String str = charBuffer.toString();
charBuffer.delete(0, charBuffer.length());
return new Token.Character(str);
} else {
isEmitPending = false;
return emitPending;
}
}
这里 state 类型 enum TokeniserState,关键地方到了。enum TokeniserState {
Data {
// in data state, gather characters until a character reference or tag is found
void read(Tokeniser t, CharacterReader r) {
switch (r.current()) {
case '&':
t.advanceTransition(CharacterReferenceInData); // 这里做状态切换
break;
case '<':
t.advanceTransition(TagOpen); // 这里也是状态切换
break;
case nullChar:
t.error(this); // NOT replacement character (oddly?)
t.emit(r.consume()); // emit()方法会将 isEmitPending 设为 true,循环结束
break;
case eof:
t.emit(new Token.EOF());
break;
default:
String data = r.consumeToAny('&', '<', nullChar);
t.emit(data);
break;
}
}
},
。。。(略)
上面的语义是当前的预期是“DATA”,如果读到'&'字符,也就是后面预期就是一个引用字符串,就把状态切换到“CharacterReferenceInData”状态,如此这般不断的切换解析,就能把整个文本分析出来。当然这样实现的前提对HTML语法要有比较深刻的理解,将所有的状态前后关联整理完善才行。TokeniserState 包含多达67个成员,即67种解析的中间状态。可以说整个html语法解析的核心。
TokeniserState,Tokeniser 是强耦合关系,循环遍历在Tokeniser 中进行,循环终止条件在TokeniserState中调用。Token解析完就要装载,这里又用到了一个enum HtmlTreeBuilderState,也有类似的状态切换,这里不再累述。
?HtmlTreeBuilder类
@Override
protected boolean process(Token token) {
currentToken = token;
return this.state.process(token, this);
}
?
2.CSS选择字符串的解析
解析后的容器是? Evaluator 匹配器类,它自身为抽象类,包含为数众多的子类实现。

